技术研发


突破!“福声计划”再传捷报,多癌风险分层模型问世,赋能大规模人群早筛精准化
近日,国际知名学术期刊Biomarker Research在线发表了复旦大学泰州健康科学研究院陈兴栋团队的最新研究成果:“Development and validation of an integrative 54 biomarker-based risk identification model for multi-cancer in 42,666 individuals: a population-based prospective study to guide advanced screening strategies”。 鹍远生物作为重要合作方深度参与。

图1. 研究成果刊发
该研究作为复旦大学泰州健康科学研究院与鹍远生物共同发起的“福声计划”中国人群泛癌早筛前瞻性研究项目的子课题,基于泰州队列长期纵向随访的人群数据,使用临床常见血液生物标志物,通过机器学习等方法构建了肺癌、食管癌、胃癌、肝癌、结直肠癌五类癌症总体预测模型(Penta-cancer Risk Identification Model, PRIME)。该研究阐明PRIME模型对大规模自然人群具有较好的多癌风险分层能力,通过对验证队列的前瞻性随访与临床医学检查,进一步表明基于PRIME模型的风险分层策略能有效区分高危人群,有助于更有效的利用早筛早检技术检出新发癌症与癌前病变。
关于“福声计划”泛癌早筛项目
“福声计划”旨在科研攻关癌症早筛早诊的适宜技术,践行我国癌症防治行动计划。项目依托“泰州队列”,由复旦大学泰州健康科学研究院与鹍远生物牵头,联合了国内11家三甲医院。项目计划建立5万例自然人群及1万例常规体检人群随访队列;构建多癌风险预测及分层模型;利用大规模前瞻性队列验证自主研发的基于甲基化及多组学的多癌筛查技术PanSeer,并实现产品产业化应用;推动建立常见恶性肿瘤的逐级精准防控体系,让大规模多癌早筛走进社区,让每一个人都能通过精准早筛,守护生命健康。
【研究方案】
癌症是全球最重要的公共卫生挑战之一,严重威胁人类健康和生命。大量研究表明,若能在早期发现癌症,不仅能够显著改善患者的预后,也能有效降低社会和家庭的医疗负担。然而,目前针对大规模人群的多癌症风险预测和分层,仍缺乏一种简便、易推广、可用于群体层面风险评估的模型或工具。这一问题亟待解决,以推动癌症早筛策略的普及与落实。
本研究基于泰州自然人群队列,根据不同周期的基线时间,设为发现队列(2011年9月-2014年1月)与验证队列(2018年7月-2021年11月),分别纳入了16,340名和26,308名40-75岁的社区中老年人,进行了持续的前瞻性随访,收集研究对象未来五年的肺癌、胃癌、肝癌、食管癌和结直肠癌发病情况。
在发现队列中,对基线收集的26个流行病学调查指标和54个生物标志物,筛选能够预测未来癌症发病的最佳变量,以此构建逐步回归(SLR)、随机森林(RF)、LASSO、支持向量机(SVM)和偏最小二乘回归(PLS)机器学习预测模型,构建了五类癌症总体预测模型(Penta-cancer Risk Identification Model, PRIME)。采用曲线下面积(AUROC)、敏感度、特异度评估模型性能。根据PRIME将研究对象划分为不同风险人群,评估模型的风险分层能力。并在亚组分析和敏感性分析中进一步评价模型的稳健性。
将PRIME应用于验证队列,于2022-2023年对高风险人群及代表性中低风险人群开展主动访视。对于知情同意的参与者,进行低剂量CT、胃肠镜、病理切片检测与B超,发现癌前病变和新发癌症,并通过检出率(yield rate)评估模型在外部队列的分层水平。
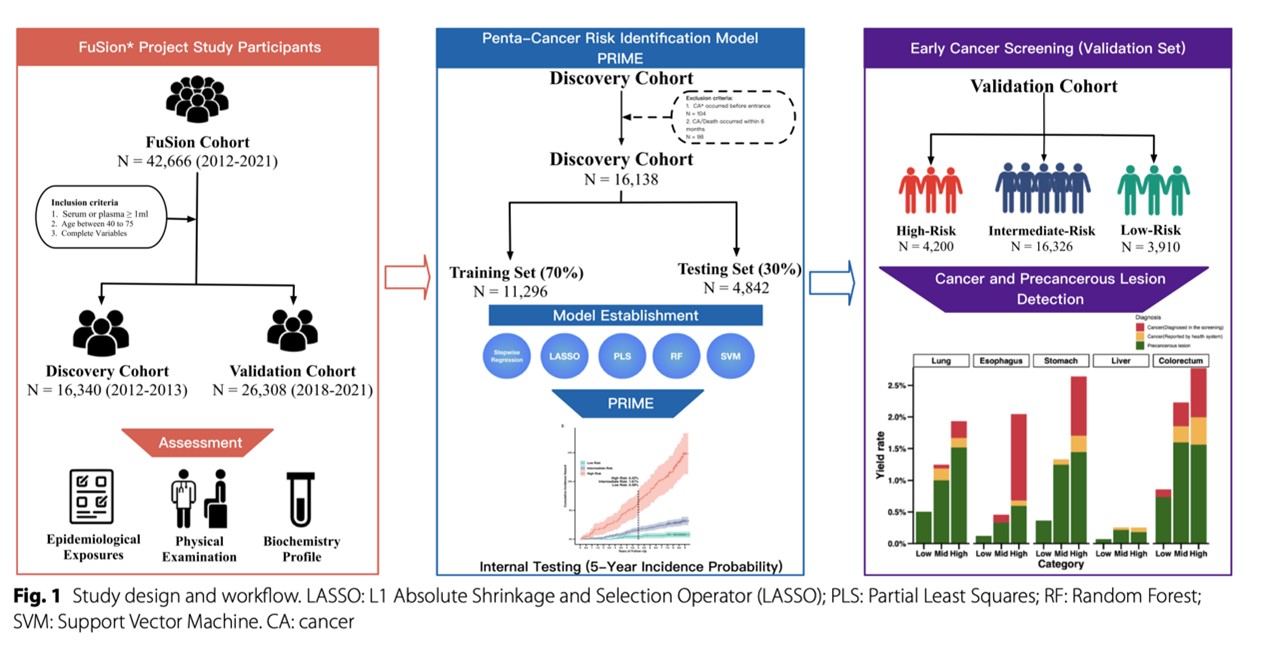
图2.研究设计
【研究结果】
1. PRIME模型有效实现高危人群分层:高风险组发病风险升高至15倍
PRIME模型在测试集中AUROC为0.768(95%CI:0.723 - 0.814;敏感度:83.72%,特异度:60.92%)。风险分层中,高风险组的粗发病率约为低风险组的16倍。累积发病率曲线显示,相比于低风险组,中风险组个体的风险增加 3.67 倍(95%CI:1.46-9.28),而高风险组个体的风险增加15.19倍(95%CI:5.97-38.64)。
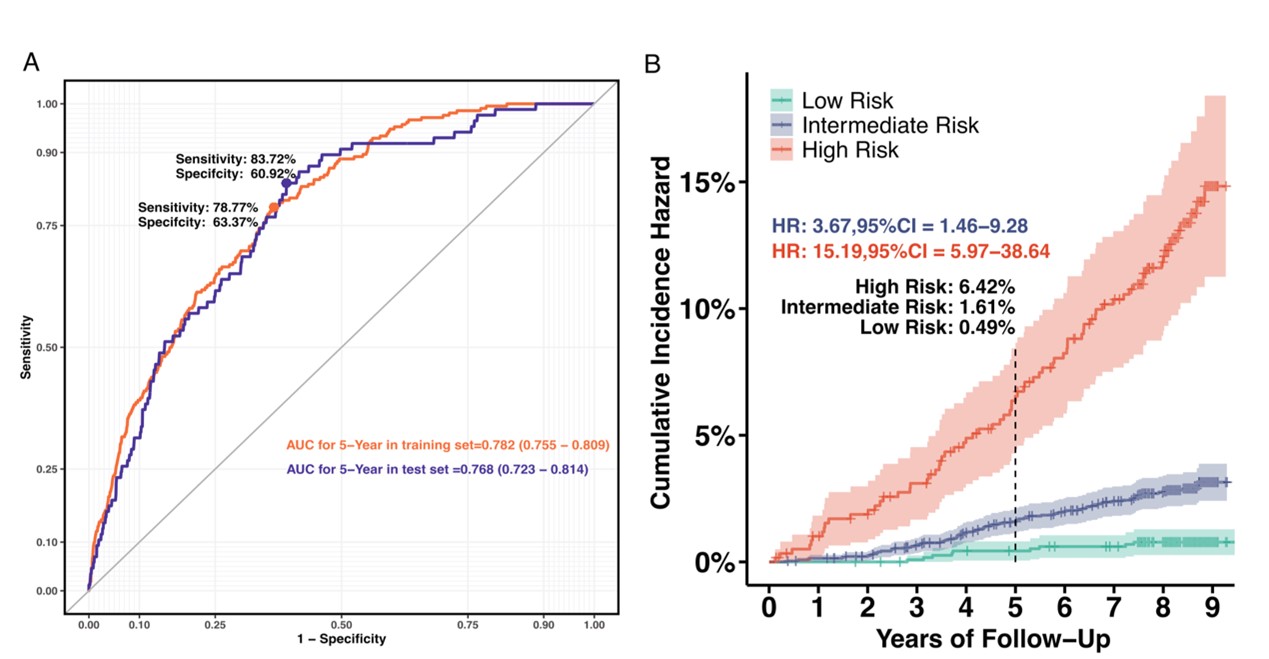
图3.测试集预测效能与风险分层
2. 开发简化评分系统与个人风险计算器,便于人群推广应用
使用基于简化评分的算法,作者团队进一步优化PRIME模型。简化模型的校准情况和预测效能与原模型一致。低风险、中风险和高风险组分别占总人口的22.78%、62.46%和14.76%。
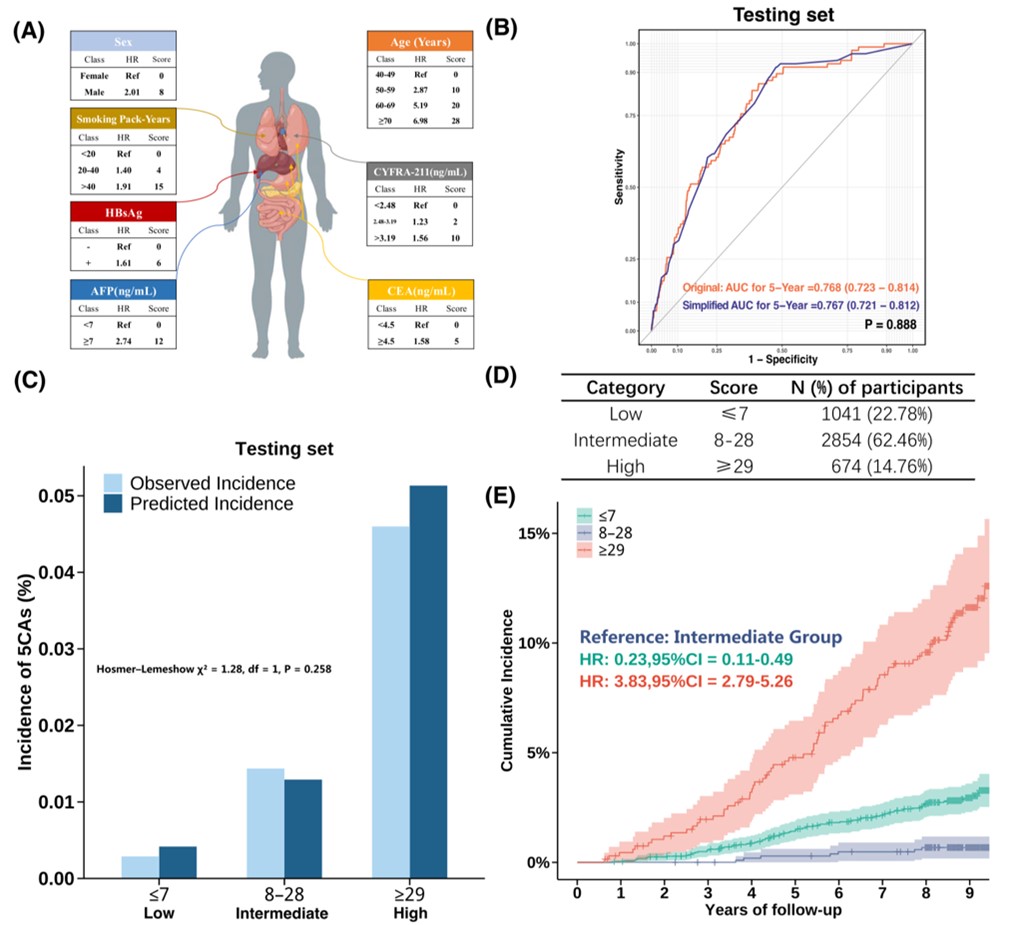
图4.简化评分系统
另外,作者团队将预测模型制作了基于网页的评分程序,以方便研究人员计算个体癌症发病风险。
3. 前瞻性验证表明PRIME模型可用于人群风险预测与分层管理
截至本次随访,有9643人参与了前瞻性随访筛查。共发现93例新发癌症病例和241例癌前病变,高风险组的癌症检出率为 9.64%,比低风险组高出5.02倍(1.92%)。食管癌的风险分层表现最为显著,高风险组检出率为低风险组的16.84倍。高风险组的总体癌症富集能力也与普通人群相比有所不同,从肝癌的1.12倍到食管癌的2.49倍不等。
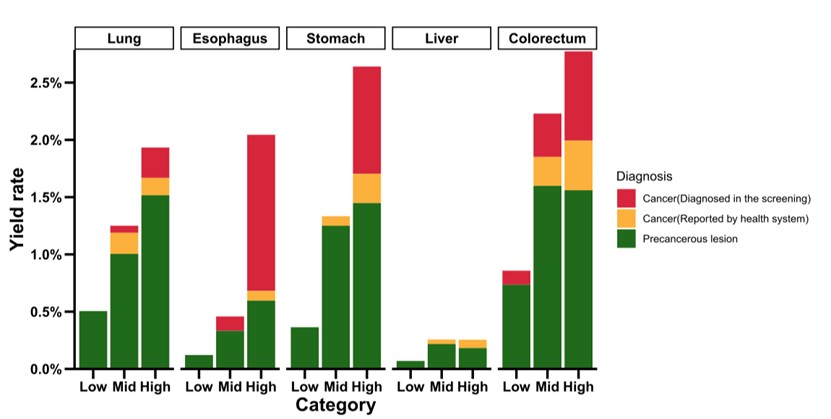
图5.验证集前瞻性随访检出率
【研究结论】
该研究使用临床常见血液生物标志物构建多癌种发病风险预测模型,在前瞻性队列中验证了该模型的预测与分层价值。利用该模型可从大规模自然人群中高效筛选高危人群,为实现癌症的精准预防、分级管理和精准医疗策略提供依据。
复旦大学人类表型组研究院博士生赵仁嘉和博士后袁黄波为本文的共同第一作者。复旦大学研究员、复旦大学泰州健康科学研究院执行院长陈兴栋,复旦大学副教授索晨为本文共同通讯作者。该研究同时得到了复旦大学金力教授、福建医科大学叶为民教授、山东大学吕明教授和鹍远生物刘蕊博士等人的指导与支持。该研究由国家自然科学基金(82473700, 82030101)、上海市科技重大专项(2023SHZDZX02,ZD2021CY001)、科技创新2030重大项目(2023ZD0510000)等项目资助。
声明:*本文仅供医学专业人士阅读参考,非广告用途。医学界力求其发表内容专业、可靠,但不对内容的准确性做出承诺;请相关各方在采用或以此作为决策依据时另行核查。




